
This article is a part of the on-going Web Scraping Series. If you are not familiar with Web Scraping please check with the first article . This session mainly deals with Dynamic Content Scraping. Nowadays most of the web portals are dynamic by making Ajax calls instead of old static web pages. Scraping on dynamic environment is both interesting and challenging one.
The first part of the discussion concentrated mainly on static page scraping with Perl mechanize module. Even though mechanize provides extension for dynamic scraping, it is not very good.
So this session deals with making use of selenium testing tool for Web Scraping.
Prerequsites
Selenium IDE is a Firefox add-on that records clicks, typing, and other actions to make a test, which you can play back in the browser.
Selenium Remote Control (RC) is a Java based Command line server for handling request from client.
Pros and Cons
It supports all Dynamic Content like Ajax, JavaScript, is easy to implement and it is possible to write selenium clients in any language we prefer, for example, here I have used Perl. You can also use Python, Java, etc.
Selenium based Web Scraping on small throughout is easy task.
It consumes lots of memory resource, for each request it will launch a new browser instance.
Working of selenium
Selenium Remote Control (RC) is a test tool that allows you to write automated web application UI tests in any programming language against any HTTP website using any mainstream JavaScript-enabled browser.
Selenium RC comes in two parts.
- A server which automatically launches and kills browsers, and acts as a HTTP proxy for web requests from them.
- Client libraries for your favourite computer language.
The RC server also bundles Selenium Core, and automatically loads it into the browser.
Here is a simplified architectural representation:
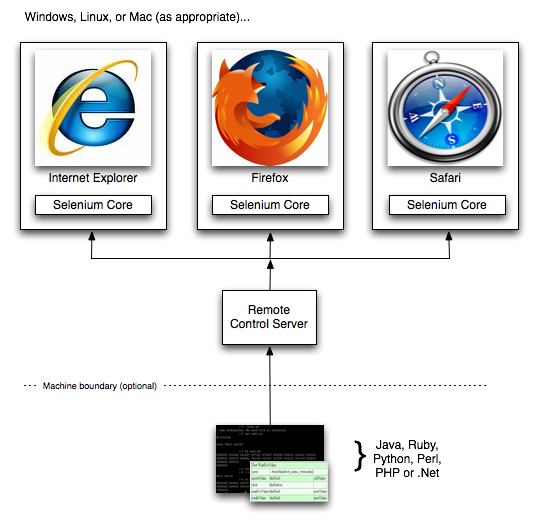
For Detailed diagram http://seleniumhq.org/about/how.html
How to Setup a Selenium Server
Download Selenium RC server to directory to /usr/local/selenium
#cd /usr/local/selenium
#unzip selenium-remote-control-1.0-beta-2-dist.zip
#cd selenium-remote-control-1.0-beta-2
#cd selenium-server-1.0-beta-2
#java -jar selenium-server.jar #starting selenium server .By default it is listen to 4444
An example Client Program
As said in the above section, it is possible to create selenium client by recording user activities or else the programmers can create it using their own language. Python, Perl and Ruby, Java has supporting modules for it.
[code]
#Sample Perl Code
#!/usr/bin/perl
use strict;
use warnings;
use Time::HiRes qw(sleep);
use Test::WWW::Selenium;
use Test::More “no_plan”;
use Test::Exception;
my $sel = Test::WWW::Selenium->new( host => “192.168.1.20”,
port => 4444,
browser => “*firefox”,
browser_url => “http://www.godaddy.com/” );
$sel->open_ok(“/domains/search.aspx?ci=8969”);
$sel->click_ok(“domain_search_button”);
$sel->wait_for_page_to_load_ok(“30000”);
my $data=$sel->get_html_source(); # here you get source of the current page
[/code]
For more info please have a look at cpan http://search.cpan.org/search?query=selenium&mode=all
As scraper you can extract required data from this source:
For scraping data from multiple pages
Open selenium IDE and record the events that you are interested and analyse the code generated and try to implement your own way,
As a last word, let me add that selenium is not completely a scraping tool, it is instead, a testing tool.
For more about selenium have look at http://seleniumhq.org/