Features Of ZFS – the Zettabyte File System – is an enormous advance in capability on existing file systems. ZFS is a combined file system and logical volume manager designed by Sun Microsystems. The features of ZFS include protection against data corruption, support for high storage capacities, efficient data compression, integration of the concepts of filesystem and volume management, snapshots and copy-on-write clones, continuous integrity checking and automatic repair, RAID-Z etc.
What Makes ZFS Different
ZFS is significantly different from any previous file system because it is more than just a file system. Combining the separate roles of volume manager and file system provides with unique advance Features Of ZFS. The file system is now aware of the underlying structure of the disks. Traditional file systems could only be created on a single disk at a time. If there were two disks then two separate file systems would have to be created. In a traditional hardware RAID configuration, this problem was avoided by presenting the operating system with a single logical disk made up of the space provided by a number of physical disks, on top of which the operating system placed a file system.ZFS’s combination of the volume manager and the file system solves this and allows the creation of many file systems all sharing a pool of available storage. One of the biggest advantages to ZFS’s awareness of the physical layout of the disks is that existing file systems can be grown automatically when additional disks are added to the pool. This new space is then made available to all of the file systems. ZFS also has a number of different properties that can be applied to each file system, giving many advantages to creating a number of different file systems and datasets rather than a single file system. Platforms were ZFS commonly used: Oracle Solaris, OpenSolaris, Nexenta, GNU/kFreeBSD, FreeBSD, zfs-fuse, FreeNAS, NAS4Free, OS X, NetBSD, MidnightBSD, ZFSGuru, DogeOS, BeleniX etc.
Features of ZFS
Some of the most appealing Features Of ZFS include:
Scalability
A key design element of ZFS file system is its Scalability. The file system itself is 128 bit, allowing for 256 quadrillion zettabyte of storage. All metadata allocated dynamically, so no need exists to preallocate inodes or otherwise limit the scalability of the file system when it is first created. All the algorithm is written in scalability in mind. Directories can have up to 256 trillion entries, and no limit exists on the number of file systems or the number of files contained within a file system.
Data Integrity
Data integrity is achieved in ZFS by checksum or has throughout the file system tree. Each block of data is checksummed and the checksum value is then saved in the pointer in that block. Next the block pointer is checksummed, with the value being saved at its pointer. This checksumming continues all the way up the file system’s data hierarchy to the root node, which is also checksummed. In-flight data corruption or phantom read/write ( the data written or read checksum correctly but is actually wrong ) are undetectable by most of file systems as they store checksum with data. Features Of ZFS stores checksum of all block in a parent pointer so that entire pool can self-validate.
When block access data, its checksum is calculated and compare it with the stored checksum value. If it matches the data are passed upon programming stack, If the checksum value do not matched with the checksum value, then ZFS can heal the data if the storage pool provide data redundancy (internal mirroring), assuming that the copy of data is undamaged and with checksum value. If the storage pool consist of one disk then it is possible to provide such redundancy by specifying copies=2 or copies=3 which means that data’s are copied twice or thrice on disk. If Redundancy exists the ZFS calculate the checksum of copied data if it matched with the actual checksum value then the data can be accessed.
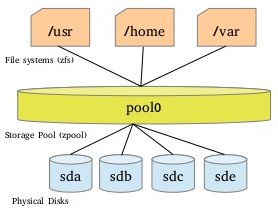
ZFS Pooled storage
In traditional file systems which resides in a single device require volume manager for adding more devices. ZFS file system are built on the top of virtual storage pool called zpool. In this we can add devices according to our requirements. Zpools contains virtual devices (vdev’s), vdev’s are configured in different ways depending on the space available (mirrored, RAID etc.).
Thus a zpool is like a RAM, total RAM capacity depends on number of RAM memory sticks and size of sticks. Likewise , a zpool consist of one or more vdev’s. Each vdev’s represents group of hard disks (or partitions or files etc.). Each vdev’s should have redundancy, because if one vdev is lost then it will effect entire zpool. Thus vdev is configured with RAID or mirror. It is possible to increase the capacity of zpool, possible to resilver (repair) the zpool. Following figure show Features Of ZFS pooled storage.
Transactional Semantics
ZFS is a transactional file system, means the file system state will be always consistent on disk. Traditional file system will overwrite data, which means when power fails the file system goes to inconsistent state. Historically this problem was solved with fsck command, which was responsible for reviewing, verifying and attempting to repair inconsistencies in file systems. But fsck was not fully guaranteed to fix all possible problems. More recently, filesystems have introduced the concept of journaling. The journaling process records actions in separate journal which can be replayed safely if a system crash occurs. But this process unnecessary overhead because data to be written twice, often resulting in new set of problems.
With transactional file system data is managed using Copy-On-Write(COW) semantics. Data is never overwritten and any of sequence is either entirely committed or entirely ignored. Thus the file system can never be corrupted during accidental power failure or system crash.
RAID
ZFS offers RAID through its RAID-Z and Mirror organization scheme.
RAID-Z is a data/parity distribution scheme like RAID-5, but uses dynamic stripe width, which means every block is its own RAID stripe, regardless of blocksize, resulting in every RAID-Z write being a full-stripe write. This, when combined with the copy-on-write transactional semantics of ZFS, eliminates the write hole error (A system crash or other interruption of a write operation can result in states where the parity is inconsistent with the data due to non-atomicity of write process, such that the parity cannot be used for recovery in the case of a disk failure). ZFS supports three levels ofRAID-Z named as RAID-Z1, RAID-Z2, RAID-Z3 based on the number of parity device and number of disks which can fail while pool remains operational.
RAID-Z1: Configuration with four disks, three disks are usable, one for parity and pool can operate in degraded mode with one faulted disk. If additional disk goes on failure before the faulted disk is replaced and resilvered, all data in the pool can be lost.
RAID-Z2: It is similar to RAID6, in which configuration with six disks, four disks are usable and two for parity. It distribute parity along with data and can lose two physical drive instead of one in RAID-Z1. RAID-Z2 is slower than RAID-Z1 because more parity to be calculated but RAID-Z2 is safer.
RAID-Z3: Configuration with eight disks, the volume will provide five disks usable space and still be able to with three faulted disks. Sun Microsystems recommends no more than nine disks in a single vdev. If the configuration has more disks, it is recommended to divide them into seperate vdevs and pool will be stripped across them.
Mirror: When creating a mirror, specifies a keyword mirror followed by list of member devices for the mirror. A mirror consist of two or more devices, all data will be written to all member devices. A mirrored vdev can withstand the failure of all but one of its members without losing data. Performance wise RAID is better than Mirroring.
Resilvering and Scrub
Resilvering, the process of copying data from one device to another device is known as resilvering. That is, if a device is replaced or gone offline, the data from up-to-date device is copied to newly restored device. The parity information distributed across remaining devices is checked and writes missing data to newly attached device.
Scrub, like fsck scrub works. Scrub is an repairing tool used in ZFS. Scrub reads all data block stored on the pool and verifies their checksums against the known checksum stored in metadata. Aperiodic check of all the data stored on the pool ensures recovery of any corrupted blocks before they needed. The checksum of each block is verified as blocks are read during normal use, but scrub make certain that even infrequently used blocks are checked for silent corruption.
Snapshot
Snapshot is the most powerful feature of the ZFS. A snapshot provides a read-only, point-in-time copy of dataset. With copy-on-write (COW), snapshots can be created quickly by preserving the older version of the data on disk. If no snapshots exist, space is reclaimed for future use when data is rewritten or deleted. Snapshots preserve diskspace by recording only the difference between the current dataset and a previous version. Snapshots are allowed only on whole datasets, not on individual files or directories. When a snapshot is created from a dataset, everything contained in it is duplicated. This includes the file system properties, files, directories, permissions, and so on. Snapshots use no additional space when they are first created, only consuming space as the blocks they reference are changed. Recursive snapshots taken with -r created with the same name on the dataset and all of its children, providing a consistent moment-in-time snapshot of all of the filesystems. This can be important when an application has files on multiple datasets that are related or dependent upon each other. Without snapshots, a backup would have copies of the files from different points in time.
Snapshots in ZFS provide variety of features that even other file systems with snapshot functionality lack. A typical example of snapshot use is to have a quick way of backing up the current state of the file system when a risky action like software installation or a system upgrade is performed. If the action fails, the snapshot can be rolled back and the system has the same state as when the snapshot was created. If the upgrade was successful, the snapshot can be deleted to free up space. Without snapshots, a failed upgrade often requires a restore from backup, which is time consuming and may require downtime during which system cannot be used. Snapshots can be rolledback quickly, even while the system is running in normal operation, with little or no downtime. The time savings are enormous with multi-terabyte storage system and the time required to copy the data from backup. Snapshots are not a replacement for a complete backup of a pool, but can be used as a quick and easy way to store a copy of the dataset at a specific point in time. ZFS filesystem can be moved from pool to pool and over network by sending snapshot.
Snapshot Rollback, the dataset will rolled back to the same state as it had when snapshot was originally taken. All the other data in that dataset that was not part of the snapshot is discarded.
Clone, is a writeable version of a snapshot. allowing filesystem to be forked as a new dataset. As with a snapshot, a clone initially consumes no additional space. As new data is written to a clone and new blocks are allocated, the apparent size of clone grows. One a clone has been created using zfs clone, the snapshot it was created from cannot be destroyed.
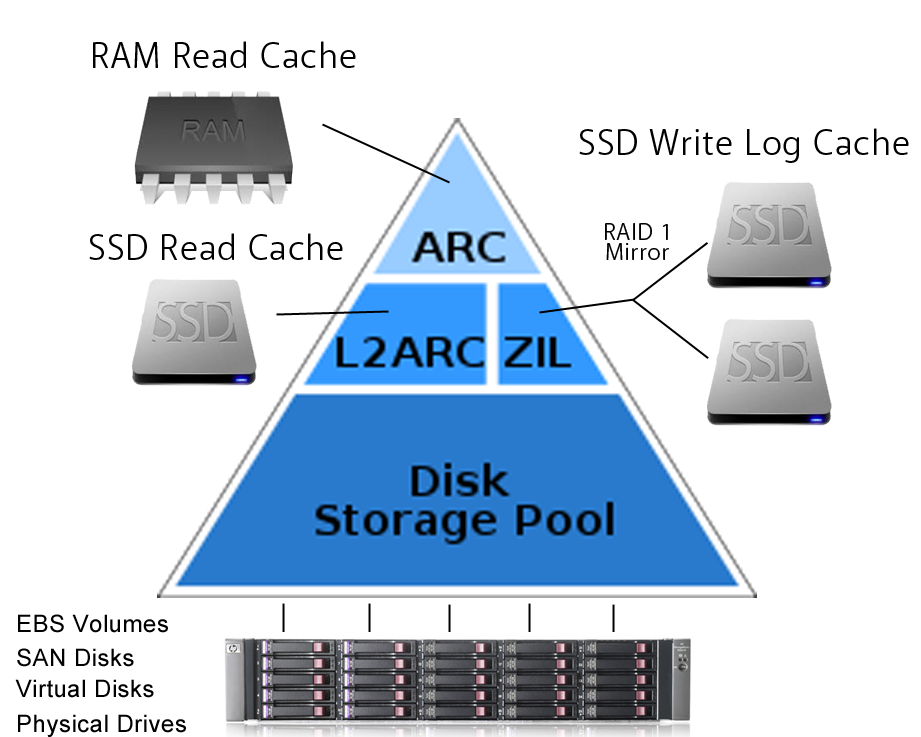
ZFS Cache
ZFS uses different layers of disk cache to speed up read and write operations. Ideally, all data should be stored in RAM, but that is too expensive. Therefore, data is automatically cached in a hierarchy to optimize performance vs cost. Frequently accessed data is stored in RAM, and less frequently accessed data can be stored on slower media, such as SSD disks. Data that is not often accessed is not cached and left on the slow hard drives. If old data is suddenly read a lot, ZFS will automatically move it to SSD disks or to RAM.
The first level of disk cache is RAM, which uses a variant of the ARC ( Adaptive Replacement Cache ) algorithm. It is similar to a level 1 CPU cache. RAM will always be used for caching, thus this level is always present. There are claims that ZFS servers must have huge amounts of RAM, but that is not true. It is a misinterpretation of the desire to have large ARC disk caches. The ARC is very clever and efficient, which means disks will often not be touched at all, provided the ARC size is sufficiently large. In the worst case, if the RAM size is very small (say, 1 GB), there will hardly be any ARC at all; in this case, Features Of ZFS always needs to reach for the disks. This means read performance degrades to disk speed.
The second level of disk cache are SSD disks. This level is optional, and is easy to add or remove during live usage, as there is no need to shut down the zpool. There are two different caches; one cache for reads, and one for writes.
L2ARC: The read SSD cache is called L2ARC and is similar to a level 2 CPU cache. The L2ARC will also considerably speed up Deduplication if the entire Dedup table can be cached in L2ARC. It can take several hours to fully populate the L2ARC.If the L2ARC device is lost, all reads will go out to the disks which slows down performance, but nothing else will happen (no data will be lost).
ZIL: The write SSD cache is called the Log Device, and it is used by the ZIL (ZFS intent log). ZIL accelerates synchronous transactions by using storage devices like SSDs that are faster than those used in the main storage pool. When an application requests a synchronous write (a guarantee that the data has been safely stored to disk rather than merely cached to be written later), the data is written to the faster ZIL storage, then later flushed out to the regular disks. This greatly reduces latency and improves performance. Only synchronous workloads like databases will benefit from a ZIL. Regular asynchronous writes such as copying files will not use the ZIL at all. If the log device is lost, it is possible to lose the latest writes, therefore the log device should be mirrored. In earlier versions of ZFS, loss of the log device could result in loss of the entire zpool, therefore one should upgrade ZFS if planning to use a separate log device.
Following figure shows the ZFS cache.
Compression
The ability to transparently compress data is more useful than one might initially realize. Not only does it save space, but in some cases it drastically improves performance. This is because the time it takes to compress or decompress the data is quicker than the time it takes to read or write the uncompressed data to disk. Currently, the following compression options are available:
LZ4 – the latest and greatest-recommended
gzip – configurable between levels 0-9, uses 6 by default – not recommended
LZJB – fast and provide a good trade-off between speed and space.
Deduplication
Features Of ZFS can potentially save a lot of disk space by using deduplication. Basically, deduplication allows to store the same data multiple times, but only take up the space of a single copy. If planning to store multiple copies of the same file(s), consider the space-saving benefits of enabling deduplication on pool or dataset. Data can be deduplicated on the file, block, or byte level.
Installing ZFS
Here ZFS is not installed as root file system. Commands for installing ZFS on some of most popular Hire remote Linux engineer distributions are shown below.
Ubuntu:
$ sudo add-apt-repository ppa:zfs-native/stable
$ sudo apt-get update
$ sudo apt-get install ubuntu-zfs
Debian:
$ su –
# wget http://archive.zfsonlinux.org/debian/pool/main/z/zfsonlinux/zfsonlinux_2%7Ewheezy_all.deb
# dpkg -i zfsonlinux_2~wheezy_all.deb
# apt-get update
# apt-get install debian-zfs
RHEL / CentOS:
$ sudo yum localinstall –nogpgcheck http://archive.zfsonlinux.org/epel/zfs-release-1-3.el6.noarch.rpm
$ sudo yum install zfs
Creating a pool
# zpool create mypool raidz1 /dev/sda1 /dev/sdb1 /dev/sdc1 /dev/sdd1
This will create /mypool and will be 6GB in size with 4 pseudo-drives of 2GB each, minus 1 for data redundancy. We can check the list of pools and get a brief overview of them by issuing
# zfs list
NAME USED AVAIL REFER MOUNTPOINT
mypool 144K 5.84G 43.4K /mypool
We can change the mount point of zpool by doing something like this during creation:
# zpool create -m /mnt mypool /dev/sda /dev/sdb /dev/sdc /dev/sdd
One of the most powerful features of ZFS is the ability to create multiple separate file systems with different settings from a common storage pool. Here we can create a “subdirectory” dataset in the root pool and enable LZ4 compression on it. We can then make another subdirectory and disable compression on it.
# zfs create mypool/usr
# zfs create -o compression=lz4 mypool/usr/ports
# zfs create -o compression=off mypool/usr/ports/distfiles
# zfs list
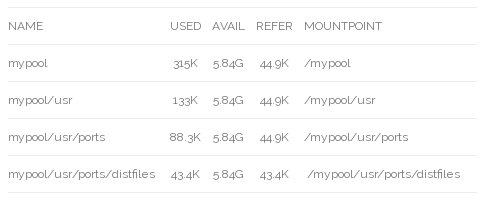
# zfs get -r compression mypool
If we look at the compression property, we can see the default applied to /usr, then our specific settings applied to /usr/ports and /usr/ports/distfiles
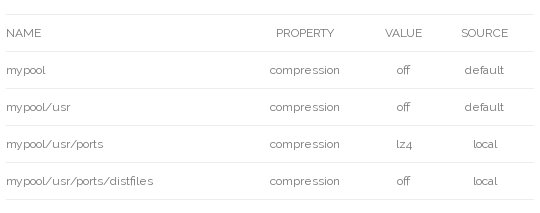
Note: Changing the compression property, and most other properties, only affects data written after the setting is applied. Enabling or disabling compression does not change data that was written previously.
To delete a zpool:
# zpool destroy mypool
Or just a specific dataset:
# zfs destroy mypool/usr
Snapshots
One of the other powerful features of ZFS is the ability to take snapshots, which allows to preserve “point in time” versions of the filesystem. Creating a 10MB file in the ports dataset:
# dd if=/dev/random of=/mypool/usr/ports/somefile bs=1m count=10
# cd /mypool/usr/ports
# ls -lh
total 10245
-rw-r–r– 1 root root 10M Nov 29 14:55 somefile
Creating a snapshot to preserve this version of the filesystem. Specify the -r (recursive) flag, it will also create a snapshot of each sub-dataset using the same snapshot name.
# zfs snapshot -r mypool/usr/ports@firstsnapshot
# zfs list -t all -o name,used,refer,written
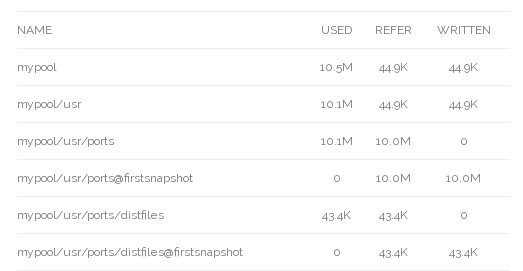
The snapshots initially take no additional space, as they only contain the data that already exists in the dataset the snapshot belongs to. If some or all of this data is overwritten, this changes. In this case we’ll overwrite the last 5 megabytes of data in the file and add an additional 5MB of data to the file:
# dd if=/dev/random of=/mypool/usr/ports/somefile bs=1m oseek=5 count=10
# zfs list -t all -o name,used,refer,written
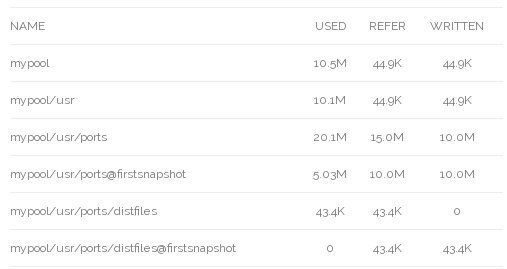
To reverse all of the files in a dataset back to how they were in a snapshot, rather than copying all of the files from the snapshot back to the dataset (which would consume double the space), Features Of ZFS has the “rollback” operation, which reverts all changes written since the snapshot:The file is now 15MB and the snapshot has grown to use 5MB of space. The 5MB of data that was overwritten has actually be preserved by the snapshot. In total, 20MB of space has been consumed – the 15MB for the current file and the 5MB of preserved overwritten data. 5MB of storage has been saved by not having to store the unmodified part of the original file twice.
Rollback
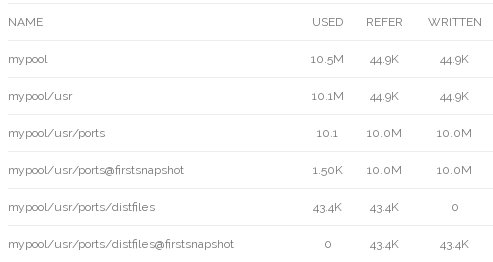
# zfs rollback -r mypool/usr/ports@firstsnapshot
# zfs list -t all -o name,used,refer,written -r mypool
Sending and Receiving Snapshots
ZFS helps to send snapshots of pool or dataset and output it to a file. We can also pipe it to other commands. This can be used to send datasets over the internet, using SSH, and receive them on a remote host. Offsite backups are a great use case for this. First, let’s take a snapshot of a dataset and redirect it to a regular file. This is a local backup.
also refer article : VIDEOJS-VS-JWPLAYER
# zfs snapshot mypool/myfiles@backup
After snap shot try to use send option and check the location for validation.
# zfs send mypool/myfiles@backup > /mnt/filesystem-backup
To restore the backup from the file,
# zfs receive -v mypool/myfiles < /mnt/filesystem-backup
Now let’s also copy that snapshot to a remote server. This is an offsite backup.
# zfs send mypool/myfiles@backup | ssh username@remoteserver zfs receive -v otherpool/myfiles
It’s also possible to do incremental data (only what’s changed since the last time) when we have multiple snapshots.
# zfs send -i mypool/myfiles@backup mypool/myfiles@laterbackup | \
ssh username@remoteserver zfs receive -v otherpool/myfiles
Data Integrity
If we have a redundant Features Of ZFS pool, the corruption will be automatically repaired and noted in the status screen. We can also initiate a manual scan of all data on the drive to check for corruption:
# zpool scrub mypool
# zpool status mypool
pool: mypool
state: ONLINE
scan: scrub in progress since Fri Sep 18 10:41:56 2015
13.8M scanned out of 13.9M at 4.60M/s, 0h0m to go
0 repaired, 99.45% done
config:
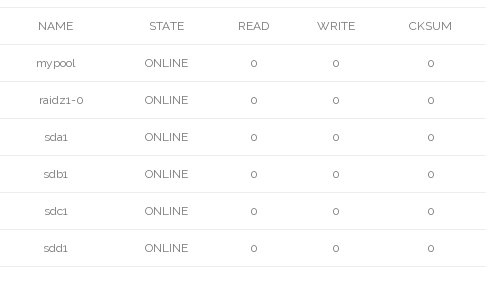
errors:No known data errors
# zpool offline mypool sda1
It will now be in degraded mode. The pools state will change to DEGRADED.
# zpool status
pool: mypool
state: DEGRADED
status: One or more devices has been taken offline by the administrator.
Sufficient replicas exist for the pool to continue functioning in a
degraded state.
action: Online the device using ‘zpool online’ or replace the device with
‘zpool replace’.
scan: scrub repaired 0 in 0h0m with 0 errors on Fri Sep 18 10:41:56 2015
config:
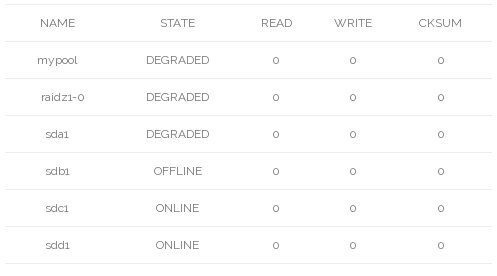
errors: No known data errors
Next we replace sda1 with sde1, resilvering
# zpool scrub mypool
# zpool status
pool: mypool
state: ONLINE
scan: resilvered 29K in 0h0m with 0 errors on Fri Sep 18 10:45:01 2015
config:
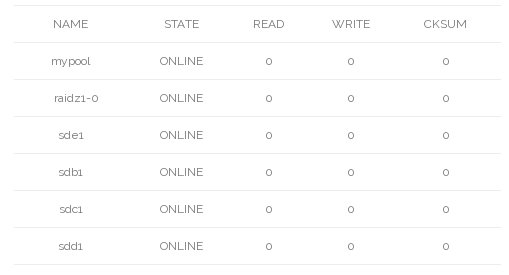
errors: No known data errors
Checksum
We can set checksum by using set,
# zfs set checksum=sha256 mypool
Other choices include “fletcher2,” “fletcher4″ and “none.”
Deduplication
# zfs create mypool/vms
# zfs set dedup=on mypool/vms
L2ARC and ZIL
The L2ARC is a caching “layer” between the RAM (very fast) and the disks (not so fast). To add an L2ARC to existing zpool, we might do:
# zpool add mypool cache /dev/ssd
A ZIL basically turns synchronous writes into asynchronous writes, improving overall performance. Let’s add one to our pool
# zpool add mypool log /dev/ssd
It’s also possible to add mirrored ZILs for even more protection.
# zpool add mypool log mirror /dev/ssd1 /dev/ssd2
SSDs make a great choice for the ZIL
reference;ZFS – Wikipedia